Research
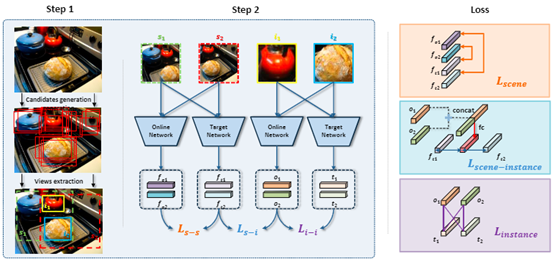
Self-Supervised Representation Learning from Arbitrary Scenarios
We theoretically prove that MAE serves as a patch-level contrastive learning, where each patch within an image is considered as a distinct category. This presents a significant conflict with global-level contrastive learning, which treats all patches in an image as an identical category. To address this conflict, this work abandons the non-generalizable global-level constraints and proposes explicit patch-level contrastive learning as a solution. Specifically, this work employs the encoder of MAE to generate dual-branch features, which then perform patch-level learning through a decoder. Our approach can learn heterogeneous representations from a single image while avoiding the conflicts encountered by previous methods. Massive experiments affirm the potential of our method for learning from arbitrary scenarios.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
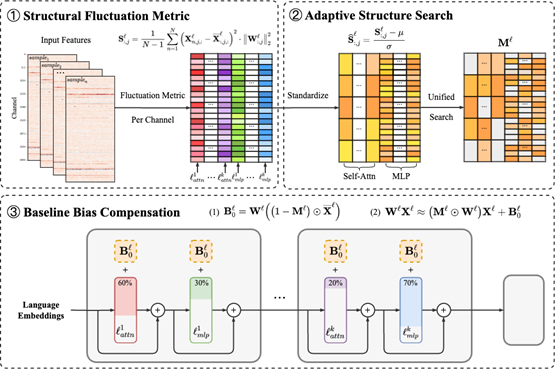
Fluctuation-based Adaptive Structured Pruning for Large Language Models [PDF] [CODE]
We propose a novel retraining-free structured pruning framework for LLMs, named FLAP (FLuctuation-based Adaptive Structured Pruning). It is hardware-friendly by effectively reducing storage and enhancing inference speed. First, FLAP determines whether the output feature map is easily recoverable when a column of weight is removed, based on the fluctuation pruning metric. Then it standardizes the importance scores to adaptively determine the global compressed model structure. At last, FLAP adds additional bias terms to recover the output feature maps using the baseline values. Without any retraining, our method significantly outperforms the state-of-the-art methods, including LLM-Pruner and the extension of Wanda in structured pruning.
Association for the Advancement of Artificial Intelligence (AAAI), 2024
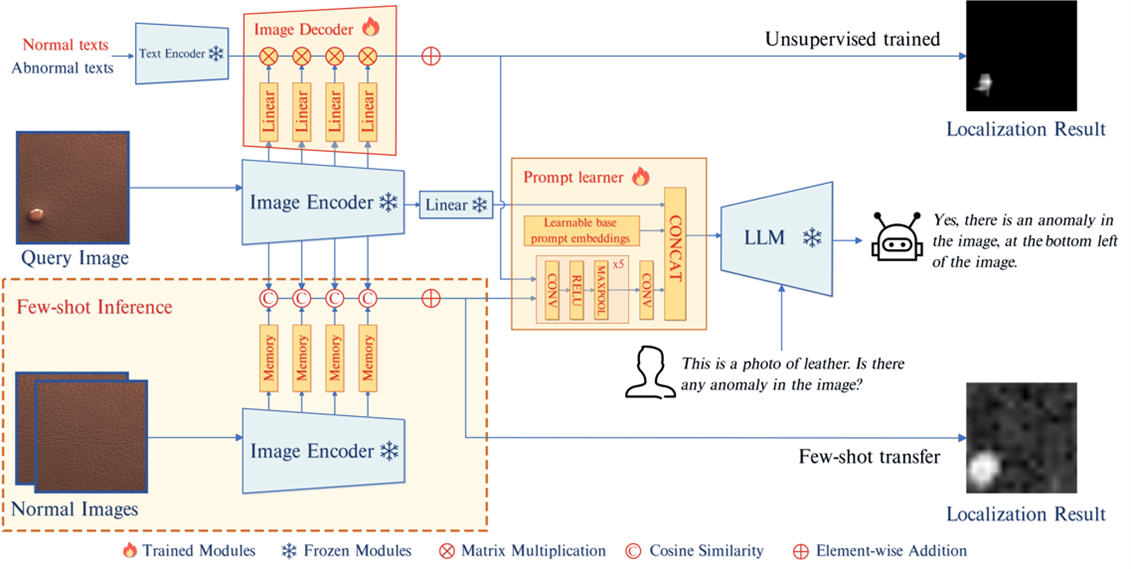
AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models [PDF] [CODE]
In this paper, we explore the utilization of Large Vision-Language Model (LVLM) to address the Industrial Anomaly Detection (IAD) problem. We generate training data by simulating anomalous images and producing corresponding textual descriptions for each image. We also employ an image decoder to provide fine-grained semantic and design a prompt learner to fine-tune the LVLM using prompt embeddings. Our AnomalyGPT eliminates the need for manual threshold adjustments, thus directly assesses the presence and locations of anomalies. Additionally, AnomalyGPT supports multi-turn dialogues and exhibits impressive few-shot in-context learning capabilities. With only one normal shot, AnomalyGPT achieves the state-of-the-art performance with an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3% on the MVTec-AD dataset.
Association for the Advancement of Artificial Intelligence (AAAI), 2024

Fast Segment Anything [PDF] [CODE]
We provides a lightweight Segment Anything(SAM) solution for the open source community. This project has achieved over 6.8k stars and 600+forks on GitHub, ranking first on the GitHub Trending list for several days and becoming a popular project on the Hugging Face platform for several consecutive days. In addition, FastSAM has been widely reported by domestic and foreign media. In terms of commercial cooperation, FastSAM has partnered with Huawei's terminal department to develop the camera function for mobile phones, and has also partnered with Tencent's Youtu department to promote the image segmentation function for game specific scenes. These cooperation cases not only demonstrate the practicality of FastSAM technology, but also demonstrate its widespread application and influence in the industry.
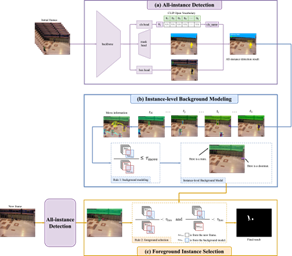
ZBS: Zero-shot Background Subtraction via Instance-level Background Modeling and Foreground Selection [PDF] [CODE]
In this work, we propose an unsupervised BGS algorithm based on zero-shot object detection called Zero-shot Background Subtraction ZBS. The proposed method fully utilizes the advantages of zero-shot object detection to build the open-vocabulary instance-level background model. Based on it, the foreground can be effectively extracted by comparing the detection results of new frames with the background model. ZBS performs well for sophisticated scenarios, and it has rich and extensible categories. Furthermore, our method can easily generalize to other tasks, such as abandoned object detection in unseen environments. We experimentally show that ZBS surpasses state-of-the-art unsupervised BGS methods by 4.70% F-Measure on the CDnet 2014 dataset.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
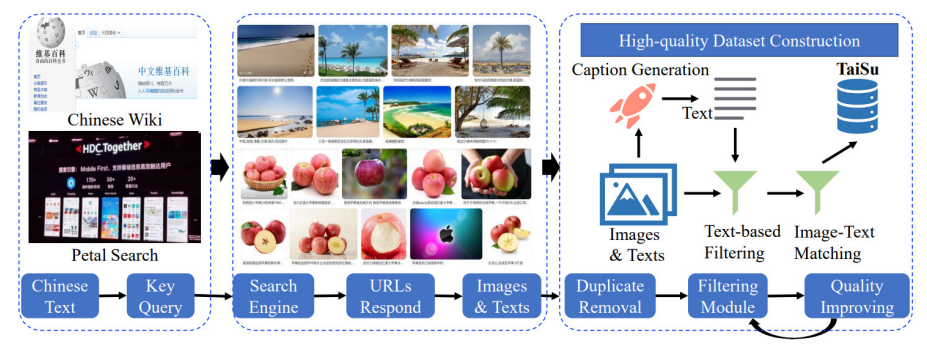
TaiSu: A 166M Large-scale High-Quality Dataset for Chinese Vision-Language Pre-training [PDF] [CODE]
Vision-Language Pre-training (VLP) has been shown to be an efficient method to improve the performance of models on different vision-and-language downstream tasks. Most of the public cross-modal datasets that contain more than 100M image-text pairs are in English; there is a lack of available large-scale and high-quality Chinese VLP datasets. In this work, we propose a new framework for automatic dataset acquisition and cleaning with which we construct a new large-scale and high-quality cross-modal dataset named as TaiSu, containing 166 million images and 219 million Chinese captions. TaiSu is currently the largest publicly accessible Chinese cross-modal dataset. Furthermore, we test our dataset on several vision-language downstream tasks. Results demonstrate that TaiSu can serve as a promising VLP dataset, both for understanding and generative tasks.
Neural Information Processing Systems (NeurIPS), 2022
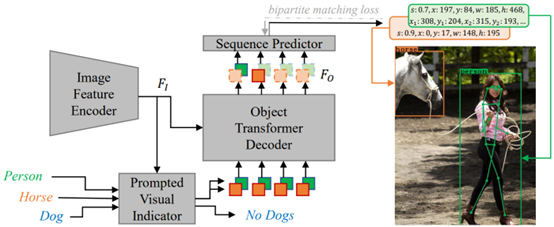
Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks [PDF] [CODE]
Visual tasks vary a lot in their output formats and concerned contents, therefore it is hard to process them with an identical structure. One main obstacle lies in the high-dimensional outputs in object-level visual tasks. In this paper, we propose an object-centric vision framework, Obj2Seq. Obj2Seq takes objects as basic units, and regards most object-level visual tasks as sequence generation problems of objects. Obj2Seq is able to flexibly determine input categories to satisfy customized requirements, and be easily extended to different visual tasks. When experimenting on MS COCO, Obj2Seq achieves 45.7% AP on object detection, 89.0% AP on multi-label classification and 65.0% AP on human pose estimation.
Neural Information Processing Systems (NeurIPS), 2022
PASS: Part-Aware Self-Supervised Pre-Training for Person Re-Identification [PDF] [CODE]
In this paper, we propose a ReID-specific pre-training method, Part-Aware Self-Supervised pre-training (PASS), which can generate part-level features to offer fine-grained information and is more suitable for ReID. PASS divides the images into several local areas, and the local views randomly cropped from each area are assigned a specific learnable [PART] token. On the other hand, the [PART]s of all local areas are also appended to the global views. PASS learns to match the outputs of the local views and global views on the same [PART]. That is, the learned [PART] of the local views from a local area is only matched with the corresponding [PART] learned from the global views. As a result, each [PART] can focus on a specific local area of the image and extracts fine-grained information of this area. Experiments show PASS sets the new state-of-the-art performances on Market1501 and MSMT17 on various ReID tasks.
European Conference on Computer Vision (ECCV), 2022
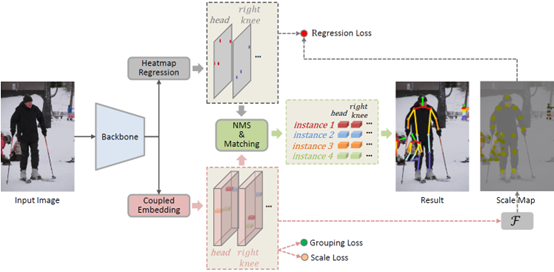
Regularizing Vector Embedding in Bottom-Up Human Pose Estimation [PDF] [CODE]
The identity embeddings of different instances are likely to be linearly inseparable in some complex scenes, such as crowded scene or when the number of instances in the image is large. To reduce the impact of this phenomenon on keypoint grouping, we try to learn a sparse multidimensional embedding for each keypoint. We observe that the different dimensions of embeddings are highly linearly correlated. To address this issue, we impose an additional constraint on the embeddings during training phase. Based on the fact that the scales of instances usually have significant variations, we utilize the scales of instances to regularize the embeddings, which effectively reduces the linear correlation of embeddings and makes embeddings being sparse. Our method achieves state-of-the-art results on CrowdPose Test (74.5 AP) and COCO Test-dev (72.8 AP), outperforming other bottom-up methods.
European Conference on Computer Vision (ECCV), 2022
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training [PDF]
Self-supervised learning (SSL) holds promise in leveraging large amounts of unlabeled data. However, the success of popular SSL methods has limited on single-centric-object images like those in ImageNet and ignores the correlation among the scene and instances, as well as the semantic difference of instances in the scene. To address the above problems, we propose a Unified Self-supervised Visual Pre-training (UniVIP) to learn versatile visual representations on either single-centric-object or non-iconic dataset. Our method outperforms BYOL by 2.5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
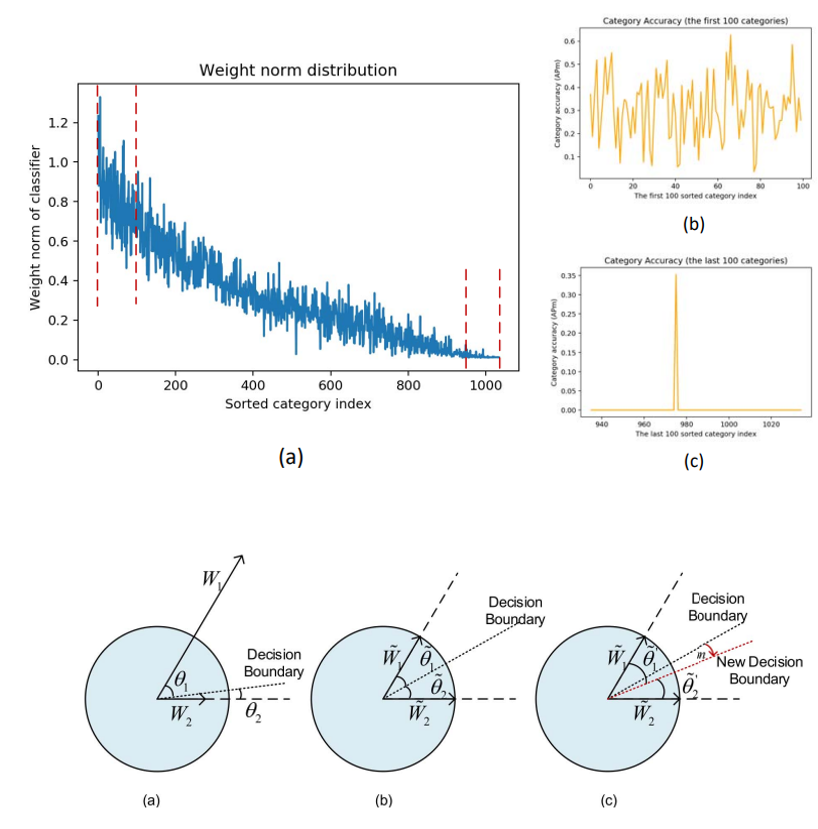
C2AM Loss: Chasing a Better Decision Boundary for Long-Tail Object Detection [PDF]
We point out that the extremely imbalanced weight norm distribution under the long-tail setting yields ill conditioned decision boundary, which severely deteri orates the performance. We present a Category-Aware Angular Margin Loss (C2AM Loss) that can adaptively adjust the decision boundary for learning a more compact and intrinsic feature representation. C2AM Loss brings obvious performance improvement (4.9%∼5.2% AP m) when compared with baseline and achieves new state-of-the-art on both LVIS v0.5 and v1.0.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
High-Performance Discriminative Tracking with Transformers [PDF] [CODE]
In this paper, we present DTT, a novel single-object discriminative tracker, based on an encoder-decoder Transformer architecture. By self- and encoder-decoder attention mechanisms, our approach is able to exploit the rich scene information in an end-to-end manner, effectively removing the need for hand-designed discriminative models. DTT is conceptually simple and easy to implement. It yields state-of-the-art performance on four popular benchmarks while running at over 50 FPS.
International Conference on Computer Vision (ICCV), 2021

Multi-initialization Optimization Network for Accurate 3D Human Pose and Shape Estimation [CODE]
Existing CNN based 3D human reconstruction methods highly depend on weak supervision signals, due to the lack of in-the-wild paired 3D supervision. However, the network easily suffers from local optima caused by the 2D-to-3D ambiguities. In this paper, we propose Multi-Initialization Optimization Network (MION) to reduce this ambiguity. In the first stage, we optimize different coarse 3D reconstruction candidates matches with a given 2D keypoints. In the second stage, we design a mesh refinement transformer (MRT) to refine each coarse reconstruction via a self-attention mechanism. Finally, a Consistency Estimation Network (CEN) is proposed to find the best result from multiple candidates via the visual evidence in RGB image. Experiments demonstrate that our MION outperforms other methods on multiple public benchmarks.
ACM Multimedia (ACM MM), 2021
DPT: Deformable Patch-based Transformer for Visual Recognition [CODE]
The fixed patch splitting in existing tranformers usually destroys the semantics of objects. To address this problem, we propose a new Deformable Patch (DePatch) module which learns to adaptively split the images into patches with different positions and scales in a data-driven way rather than using predefined fixed patches. In this way, our method can well preserve the semantics in patches. As it can work as a plug-and-play module, we build a Deformable Patch-based Transformer (DPT) and conduct extensive experiments on image classification and object detection. Results indicates that our method can bring significant improvements.
ACM Multimedia (ACM MM), 2021
Improving Multiple Object Tracking with Single Object Tracking [PDF]
We propose a novel and end-to-end trainable MOT architecture that extends CenterNet by adding an SOT branch for tracking objects in parallel with the existing branch for object detection, allowing the MOT task to benefit from the strong discriminative power of SOT methods in an effective and efficient way. The added SOT branch trains a separate SOT model per target online to distinguish the target from its surrounding targets, assigning SOT models the novel discrimination. The proposed tracker achieves IDF1s of 0.719 and 0.714 on MOT17 and MOT20 benchmarks, respectively, while running at 16 FPS on MOT17.
Internaltional Conference on Computer Vision and Pattern Recogintion (CVPR), 2021

Adaptive Class Suppression Loss for Long-Tail Object Detection [CODE]
We devise a novel Adaptive Class Suppression Loss (ACSL) to protect the training of tail categories and perform discriminative learning between semantically similar categories. Specifically, we introduce a statistic-free perspective to analyze the long-tail distribution, breaking the limitation of manual grouping. According to this perspective, our ACSL adjusts the suppression gradients for each sample of each class adaptively, ensuring the training consistency and boosting the discrimination for rare categories. Extensive experiments on long-tail datasets LVIS and Open Images show that the our ACSL achieves 5.18% and 5.2% improvements with ResNet50-FPN, and sets a new state of the art.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021

Identity-Guided Human Semantic Parsing for Person Re-Identification [PDF] [CODE]
We propose the identity-guided human semantic parsing approach (ISP) to locate both the human body parts and personal belongings at pixel-level for aligned person re-ID only with person identity labels. We design the cascaded clustering on feature maps to generate the pseudo-labels of human parts. Specifically, for the pixels of all images of a person, we first group them to foreground or background and then group the foreground pixels to human parts. The cluster assignments are subsequently used as pseudo-labels of human parts to supervise the part estimation and ISP iteratively learns the feature maps and groups them.
European Conference on Computer Vision (ECCV), 2020

Blended Grammar Network for Human Parsing
we propose a Blended Grammar Network to exploit the inherent hierarchical structure of a human body and the relationship of different human parts by means of grammar rules in both cascaded and paralleled manner. In this way, conspicuous parts, which are easily distinguished from the background, can amend the segmentation of inconspicuous ones, improving the foreground extraction. Our method obtains state-of-the-art performance on PASCAL-Person-Part, LIP, and PPSS datasets.
European Conference on Computer Vision (ECCV), 2020

Adaptive Variance Based Label Distribution Learning for Facial Age Estimation [PDF]
One of the most intractable issues for facial age estimation is label ambiguity. Some existing methods adopt distribution learning to tackle this issue. Actually, most of them set a fixed value to the variance of Gaussian label distribution for all the images. However, the variance is closely related to the correlation between adjacent ages and should vary across ages and identities. In this paper, we propose an adaptive variance based distribution learning (AVDL) method for facial age estimation. AVDL introduces the data-driven optimization framework, meta-learning, to achieve this. Extensive experiments on FG-NET and MORPH II datasets show the superiority of our proposed approach to the existing state-of-the-art methods.
European Conference on Computer Vision, ECCV (2020)
Learning Feature Embeddings for Discriminant Model based Tracking [PDF] [CODE]
After observing that the features used in most online discriminatively trained trackers are not optimal, in this paper, we propose a novel and effective architecture to learn optimal feature embeddings for online discriminative tracking. Our method, called DCFST, integrates the solver of a discriminant model that is differentiable and has a closed-form solution into convolutional neural networks. Then, the resulting network can be trained in an end-to-end way, obtaining optimal feature embeddings for the discriminant model-based tracker. Extensive experiments on six public benchmarks show that our approach achieves state-of-the-art accuracy, while running beyond the real-time speed.
European Conference on Computer Vision, ECCV (2020)

Large Batch Optimization for Object Detection: Training COCO in 12minutes [PDF]
We propose a versatile large batch optimization framework for object detection, named LargeDet, which successfully scales the batch size to larger than 1K for the first time. Specifically, we present a novel Periodical Moments Decay LAMB (PMD-LAMB) algorithm to effectively reduce the negative effects of the lagging historical gradients. Additionally, the Synchronized Batch Normalization (SyncBN) is utilized to help fast convergence.
European Conference on Computer Vision (ECCV) 2020

Task Decoupled Knowledge Distillation For Lightweight Face Detectors [PDF] [CODE]
We propose a knowledge distillation method for the face detection task. This method decouples the distillation task of face detection into two subtasks, i.e., the classification distillation subtask and the regression distillation subtask. We add the task-specific convolutions in the teacher network and add the adaption convolutions on the feature maps of the student network to generate the task decoupled features. Then, each subtask uses different samples in distilling the features to be consistent with the corresponding detection subtask. Moreover, we propose an effective probability distillation method to joint boost the accuracy of the student network.
ACM Multimedia (ACM MM), 2020

Part-aware Context Network for Human Parsing
We propose a novel Part-aware Context Network (PCNet) to deal with a challenge of how to generate adaptive contextual features for the various sizes and shapes of human parts. PCNet consists a relational aggregation module to capture the representative global context by mining associated semantics of human parts, and a relational dispersion module to generate the discriminative and effective local context and neglect disturbing one by making the affinity of human parts dispersed.
Computer Vision and Pattern Recognition (CVPR), 2020

Progressive Bi-C3D Pose Grammar for Human Pose Estimation
We propose a progressive pose grammar network learned with Bi-C3D (Bidirectional Convolutional 3D) for human pose estimation. Firstly, a local multi-scale Bi-C3D kinematics grammar is proposed to promote the message passing process among the locally related joints. The multi-scale kinematics grammar excavates different levels human context learned by the network. Moreover, a global sequential grammar is put forward to capture the long-range dependencies among the human body joints. The whole procedure can be regarded as a local-global progressive refinement process.
The Association for the Advancement of Artificial Intelligence (AAAI), 2020

Attention CoupleNet for Object Detection [PDF]
We propose a novel fully convolutional network, named as Attention CoupleNet, to incorporate the attention-related information and global and local information of objects to improve the detection performance. Specifically, the proposed method effectively exploits the cascade attention structure to gradually focus on the target regions by generating several class-agnostic attention feature maps. Then, the attention maps are encoded into the network to acquire object-aware features.
IEEE Transactions on Image Processing (TIP), 2019

Fast-deepKCF Without Boundary Effect [PDF] [Code]
fdKCF* casts aside the popular acceleration tool, fast Fourier transform, employed by all existing CF trackers, and exploits the inherent high-overlap among real, ie, noncyclic, and dense samples to efficiently construct the kernel matrix of KCF. fdKCF* enjoys the following three advantages. (i) It is efficiently trained in kernel space and spatial domain without the boundary effect. (ii) Almost all repeated calculations are eliminated, and the remaining ones are accelerated with GPU. Its fps is almost independent of the number of feature channels. Therefore, it is almost real-time, even though the high-dimensional deep features are employed. (iii) Its localization accuracy is state-of-the-art.
International Conference on Computer Vision (ICCV), 2019
Feature Distilled Tracking [PDF]
To reduce the computational complexity of deep CNN models in visual tracking, we propose a small feature distilled network (FDN) by imitating the intermediate representations of a much deeper network for obtaining small and fast-to-execute shallow models based on model compression. To further speed-up, we introduce a shift-and-stitch method to reduce the arithmetic operations, while preserving the spatial resolution of the distilled feature maps unchanged. Comprehensive experiments on tracking benchmarks show that the proposed approach achieves 5x speed-up with competitive performance to the state-of-the-art deep trackers.
IEEE Transactions on Cybernetics, 2019

Two-level Attention Network for Vehicle Re-identification [PDF]
We propose a two-level attention network, consisting of hard part-level attention and soft pixel-level attention, to adaptively extract discriminative features from the visual appearance of vehicles. The former one is designed to localize the salient vehicle parts like windscreen and car-head. The later one gives an additional attention refinement at pixel level to focus on the distinctive characteristics within each part. The proposed network can learn comprehensive and discriminative feature representations and achieve the SOTA performance on three large-scale datasets.
IEEE Transactions on Image Processing(TIP), 2019

Semantic Alignment for Facial Landmark Detection [PDF]
The semantic ambiguity caused by inconsistent annotations greatly degrades the facial landmark detection performance. To address this problem, we propose a novel probabilistic model which introduces a latent variable to represent the “real” ground-truth. The framework couples two parts: training landmark detection CNN and searching the “real” ground-truth, which are alternatively optimized. In addition, we propose a global heatmap correction unit to recover the unconfidently predicted landmarks due to occlusion and low quality, by considering the global face shapes as a constraint. Extensive experiments on image-based and video-based datasets demonstrate the effectiveness of our method.
Computer Vision and Pattern Recognition (CVPR), 2019

Gate-based Bidirectional Interactive Decoding Network for Scene Text Recognition [PDF]
Recent dominant approaches typically follow an attention-based encoder-decoder framework that uses a unidirectional decoder to perform decoding in a left-to-right manner, but ignoring equally important right-to-left grammar information. We propose a novel Gate-based Bidirectional Interactive Decoding Network (GBIDN) to excavate the global grammatical information in text sequences. The bidirectional grammar information is fully fused through the interaction of the bidirectional decoders, and the visual context information is also combined to exploit the complementary advantages of different information. Through a gated context mechanism, the fusion process is adjusted to reduce the influence of noise, thus achieving more accurate decoding.
International Conference on Information and Knowledge Management (CIKM), 2019
High-speed Tracking with Multi-kernel Correlation Filters [PDF] [Code]
Although MKCF achieves more powerful discriminability than KCF through introducing multi-kernel learning (MKL) into KCF, its improvement over KCF is quite limited and its computational burden increases significantly in comparison with KCF. To address these problems, the MKL version of CF objective function is reformulated with its upper bound, alleviating the negative mutual interference of different kernels significantly. Then, an efficient approximate solution is derived to keep the novel MKCF, MKCFup, running at very high fps. MKCFup outperforms KCF and MKCF with large margins and is still comparable to KCF in efficiency.
Computer Vision and Pattern Recognition (CVPR), 2018

Coarse-to-fine Feature Embedding for Vehicle Re-identification [PDF] [Dataset]
There exists complex intra- and inter-class variations for vehicle re-identification. To address this problem, we propose a structured feature embedding learning framework by exploiting an efficient coarse-to-fine ranking loss to pull images of the same vehicle as close as possible and achieve discrimination between images from different vehicles as well as vehicles from different vehicle models. Furthermore, to facilitate the research development, we build so far the largest vehicle re-ID dataset “Vehicle-1M” which involves nearly 1 million images captured in various surveillance scenarios.
The Association for the Advancement of Artificial Intelligence (AAAI), 2018

Progressive Cognitive Human Parsing [PDF]
We develop an end-to-end progressive cognitive network to segment human parts. In order to establish a hierarchical relationship, a novel component-aware region convolution structure is proposed. With this structure, latter layers inherit prior component information from former layers and pay its attention to a finer component. In this way, we deal with human parsing as a progressive recognition task, that is, we first locate the whole human and then segment the hierarchical components gradually.
The Association for the Advancement of Artificial Intelligence (AAAI), 2018

CoupleNet: Coupling Global Structure with Local Parts for Object Detection [PDF] [Code]
We present the CoupleNet, a concise yet effective network that simultaneously couples global, local and context cues for accurate object detection. Our system naturally combines the advantages of different region-based approaches with the coupling structure. With the combination of local part representation, global structural information and the contextual assistance, our CoupleNet achieves state-of-the-art results on the challenging PASCAL VOC and COCO datasets without using any extra tricks in the testing phase.
International Conference on Computer Vision (ICCV), 2017

Fast Deep Matting for Portrait Animation on Mobile Phone [PDF]
We propose a real-time automatic deep matting approach for mobile devices. By leveraging the densely connected blocks and the dilated convolution, a light full convolutional network is designed to predict a coarse binary mask for portrait images. And a feathering block, which is edge-preserving and matting adaptive, is further developed to learn the guided filter and transform the binary mask into alpha matte.
ACM Multimedia Conference (ACM MM), 2017