Introduction
The online handwritten document database, CASIA-onDo, serving as a standard database for the development and evaluation of methods in the field of online handwritten document layout analysis, was built by the National Laboratory of Pattern Recognition (NLPR), Institute of Automation of Chinese Academy of Sciences (CASIA). CASIA-onDo consists of 2,012 documents which were created from 1000 document templates with various complexity. The database, covering Chinese and English, was produced by 200 writers using Huawei tablets. Generally, each individual template was copied by 2 different writers, and each writer drew 10 different documents. Each document contains a number of handwritten strokes, and each stroke is a sequence of trajectory points recording xy-coordinates, pressure, pen-state and time. Six content types occur in the documents, namely text, formulas, diagrams, tables, drawings, and lists.
The CASIA-onDo database is packed in zip archive. Please click the link below for download.
CASIA-onDo.zip (200MB)
A comprehensive description of the database has been accepted by 6th Asian Conference on Pattern Recognition (ACPR2021). Please refer to and cite Yu-Ting Yang, Yan-Ming Zhang, Xiao-Long Yun, Fei Yin and Cheng-Lin Liu, "CASIA-onDo: A New Database for Online Handwritten Document Analysis," in ACPR2021.
Annotation
We provide two levels of annotations for each stroke: the semantic class and instance ID of its associate symbol.
For semantic annotation, we provide 11 semantic labels in total rather than 6 labels listed in Introduction to facilitate multiple usage of the dataset,as shown in Table 1. In particular, formula class are divided into four subclasses: in-line formula, inter-line formula, in-list formula and in-diagram formula. The diagram is refined into the symbols within the diagram, the text within the diagram, and the formulas within the diagram. The table is refined into table lines and text within the table. In annotating formulas, isolated numbers or variables (such as 8, a) are not marked as formulas, while math expressions with 2-dim layout (such as 82, a2) and special mathematical symbols (such as π, ∑, ∞) are marked as formulas regardless of their length. In annotating lists, as long as there is a symbol in front of each item, regardless of the length and number, it is marked as a list. The colored annotation of document is shown in Figure 1.
Table 1. Annotations of CASIA-onDo
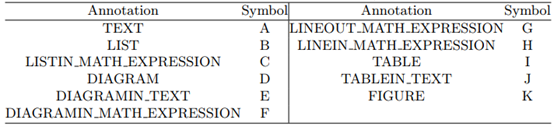
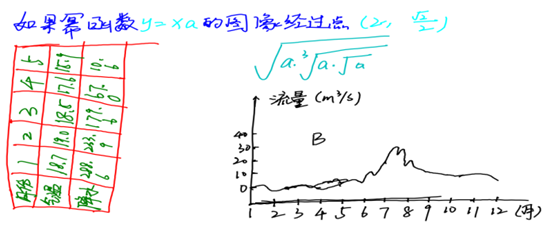
Figure 1. An example of annotated online document in CASIA-onDo. Classes are denoted by different colors.
For instance level annotation, each text line is treated as an instance with a unique ID. For the remaining five categories, different entities have different IDs. We choose the InkML(Ink Markup Language) language to store the documents, which can represent information flexibly. This is mainly achieved through two elements. The first one is the trace element. This XML tag represents a stroke. It contains a stroke ID and a sequence of trajectory points with a variable-length. The second one is the traceGroup element, which records a collection of strokes belonging to the same category. The label exists in its child element annotationXML in the format of ”label_id”, where ”label” represents which content type the group of strokes belong to, and ”id” is used to distinguish different instances
Data Partitioning
The documents are randomly divided into three disjoint subsets——a training set, a validation set and a test set at the ratio of 7:1:2. Therefore, there are 1400/200/412 documents in the training/validation/test set, respectively. The statistics details of the CASIA-onDo dataset are shown in Table 2. The file list of training set, validation set and test set are stored in file “training.set”, “validation.set”, “test.set”, respectively.
Table 2. The statistics details of the CASIA-onDo dataset

Recommendations of usage
1) Stroke classification: CASIA-onDo is made up of a large number of strokes, grouped into six categories. For different levels of classification, user can use the annotations from Table 2 to generate appropriate labels neatly.
2) Text separation and formula segmentation: CASIA-onDo contains 5046 text lines and 7406 formulas in total. What’s more, all the instances are separated in the ground-truth. It is convenient for training and evaluating text line segmentation and formula segmentation algorithms.
3) Writer identification: All the documents are stored in writer-specific files and each writer has 10 handwritten pages. We can perform experiments to judge whether two documents are from the same writer or not(writer verification) or classify a page to a nearest reference page of known writer(writer identification).
Condition of Use
The online handwritten documen database, CASIA-onDo, built by the CASIA, are released for academic research free of cost under an agreement.
Commercial use of the databases is subject to charge. For possible license of commercial use, please contact Fei Yin ( fyin@nlpr.ia.ac.cn). The database of commercial use is enlarged to contain all the online handwritten documents.
The application form of the dataset for academic research can be downloaded bellowing:
Conditions of Academic Use
1. All samples in the databases under this agreement can only be used by the group of the named applicant and can only be used for research purpose. No samples can be used for any commercial purpose.
2. The Institute of Automation of CAS retains the copyright of all sample data in the databases.
3. Publications of research results on the database should be appropriately acknowledged.
Contact
Cheng-Lin Liu ( liucl@nlpr.ia.ac.cn), Yan-Ming Zhang ( ymzhang@nlpr.ia.ac.cn)
National Laboratory of Pattern Recognition (NLPR)
Institute of Automation of Chinese Academy of Sciences
95 Zhongguancun East Road, Beijing 100190, P.R. China
24th International Conference on Pattern Recognition
15th International Conference on Frontiers in Handwriting Recognition
10th IAPR-TC15 Workshop on Graph-based Representations in Pattern Recognition
Haidian | Beijing | China
Phone : (+86-10)8254-4797
Fax : (+86-10) 8254-4594
Email:liucl@nlpr.ia.ac.cn
Website:www.nlpr.ia.ac.cn/pal/