| |
TASK DESCRIPTION
One critical but challenging problem in natural language understanding (NLU) is to develop a question answering system which could consistently understand and correctly answer general questions about the world. "Multi-choice Question Answering in Exams" is a typical question answering task that aims to test how accurately the participants could answer the questions in exams. The questions in this competition come from real exams. We believe that this challenge is an important step towards a rational, quantitative assessment of NLU’s capabilities.
This challenge collects multiple choice questions from a typical science and history curriculum. All questions are restrained within the elementary and middle school level. For each question, there are four possible answers, where each of them may be a word, a value, a phrase or even a sentence. The participants are required to select the best one from these four candidates. To answer these questions, participants could utilize any public toolkits and any resources on the Web, but manually annotation is not permitted. The following is an example.

DATA FORMAT/SIZE
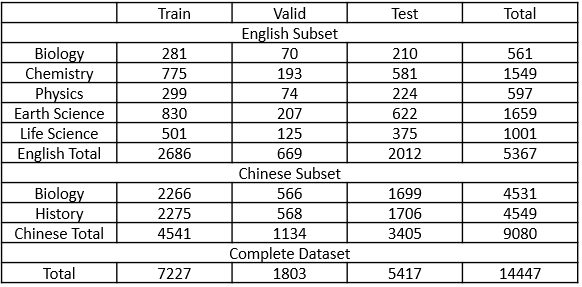
In order to explore the influence of diversity of questions, we collect questions from seven subjects in two languages, including an English subset and a Chinese subset. The subjects of English subset contain biology, chemistry, physics, earth science and life science. And the subjects of Chinese subset contain biology and history. The total number of questions is 14,447.
Data Format
Each line of data is like:
id,”question”,”answerA”,”answerB”,”answerC”,”answerD”,correctAnswer
The meaning of each field is shown as follows.
- id - unique integer id for each question
- question - the question text
- answerA - the text for answer option A
- answerB - the text for answer option B
- answerC - the text for answer option C
- answerD - the text for answer option D
- correctAnswer - the correct answer (0,1,2,3, which correspond to four options. Only available for Train set and Valid Set)
Data Size
The dataset totally contains 14,447 multiple choice questions. In detail, English subset contains 5,367 questions and Chinese subset contains 9,080 questions. We randomly split the dataset into Train, Validation and Test sets. And more detail statistics is showed as follows.
Corpus
We encourage participants utilize any resources in the Internet, including software, toolbox, and corpus. There may be useful corpus shown as follows.
Wikipedia dumps: https://dumps.wikimedia.org/
ConceptNet 5: http://conceptnet5.media.mit.edu/downloads/
DBpedia: http://wiki.dbpedia.org/downloads-2016-04
Textbook: http://www.ck12.org/browse/
DATA LICENSE
We collect questions from Internet and all questions only can be used for this Task. It is forbidden to distribute this dataset and to use this dataset for commercial purposes.
RELATED WORK
Aristo is a system to answer a variety of science questions from standardized exams for students in multiple grade levels. It is developed by Allen Institute for Artificial Intelligence (AI2), and it integrates several promising solvers, including IR Solver, PMI Solver, SVM Solver, Rule-based solver, ILP solver. There are related materials at http://allenai.org/papers.html#aristo.
SCORER
This challenge employs the accuracy of a method on answering questions in test set as the metric, the accuracy is calculated as
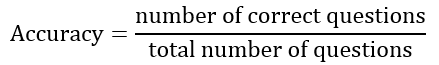
English subset and Chinese subset are evaluated individually, and participants can submitted results for one or both two subsets.
BASELINE
We employ a simple retrieval based method as a baseline, and it is implemented based on Lucene
which is an open-source information retrieval software library. We employ the method to build
reverse-index on the whole Wikipedia dump for English questions and on the Baidu Baike corpus for Chinese questions.
This method scores pairs of the question and each of its option, the detail steps are shown as follows.
- Concatenate a question with an option as the query;
- Use Lucene to search relevant documents with the query;
- Score relevant documents by the similarity between the query q and the document d, noted as Sim(q,d)
- Choose at most three highest scores to calculate the score of the pair of the question and the option as
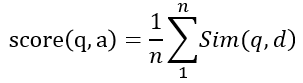
where n is less than or equals to 3 and if n = 0, score(q, a)=0;
- The pair with highest score(q,a) is the answer outputted by this method.
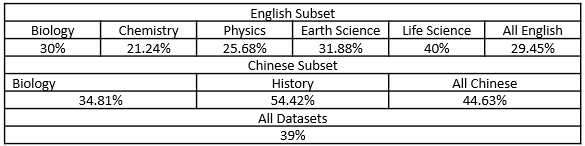
All questions and options are preprocessed by Stanford CoreNLP. The detail result of the baseline on the validation set is shown as follows
SCHEDULE
- First Call for Participants Ready: May 1, 2017
- Registration Begins: May 15, 2017
- Release of Training and Development Data: May 15, 2017
- Registration Ends: August 11, 2017
- Release of Test Set: August 14, 2017
- Submission of Systems: August 30, 2017
- System Results: August 31, 2017
- System Description Paper Due: September 15, 2017
- Notification of Acceptance: September 30, 2017
- Camera-Ready Deadline: October 10, 2017
SUBMITTED SYSTEM
We set up a simple and automatic evaluation system to evaluate the results from participators. Each question has a question id, and the result file should exactly have the same lines with the test set. Each line contains the question id, and the answer option (A, B, C or D), and the order of lines is arbitrary. The format of submission file is shown below. After submission, our evaluation system will judge it and give the accuracy.
Submission Format
Question id, selected answer
Example
Question_id1,D
Question_id2,A
Question_id3,C
Question_id4,D
Question_id5,B
Question_id6,A
Entrance of Submission System
Click here to submit your solution for validation set.
Click here to submit your solution for test set.
The result file need to be submitted by our system on the website, and we require that the name of submission file must be as follows.
TeamID_en.csv for English subset.
TeamID_zh.csv for Chinese subset.
TeamID_all.csv for both of subsets.
TASK ORGANIZER
Jun Zhao, Institute of Automation, Chinese Academy of Sciences, (jzhao@nlpr.ia.ac.cn)
Kang Liu, Institute of Automation, Chinese Academy of Sciences, (kliu@nlpr.ia.ac.cn)
Shizhu He, Institute of Automation, Chinese Academy of Sciences, (shizhu.he@nlpr.ia.ac.cn)
Zhuoyu Wei, Institute of Automation, Chinese Academy of Sciences, (zhuoyu.wei@nlpr.ia.ac.cn)
Shangmin Guo, Institute of Automation, Chinese Academy of Sciences, (shangmin.guo@nlpr.ia.ac.cn)
Contact
mcqa.ijcnlp@outlook.com
|