
|
|
Face Group Projects |
Face Technologies
This project is aimed to develop techniques and algorithms for automated face recognition. The research topics include detection, tracking, pose estimation, alignment, and recognition of multi-view faces, where multi-view means reasonable amount of in-plane, out-of-plane and up-down rotations. The structure of the current system is shown in the figure below. The system takes gray level static images or video as the input, without using color or motion information, and finds the locations, sizes, poses of faces in the input, and recognize their identities; all these are done in real-time. The system also includes internal feedback mechanisms for collecting and adding to the training sets new face examples for re-training the performing modules.
Our objective has been to make these components work practically, fast and robustly. The methodology used to achieve this has evolved from our previous expensive nonlinear models [Li-SVR-ICCV-01,Li-SVR-RTSFG-01] to the current efficient linear models for face detection and alignment [Zhang-FD,Li-DAM], and from the previous unsupervised learning [Li-ISA-ICCV-01] to current supervised learning [Li-View-ICA] for pose estimation.
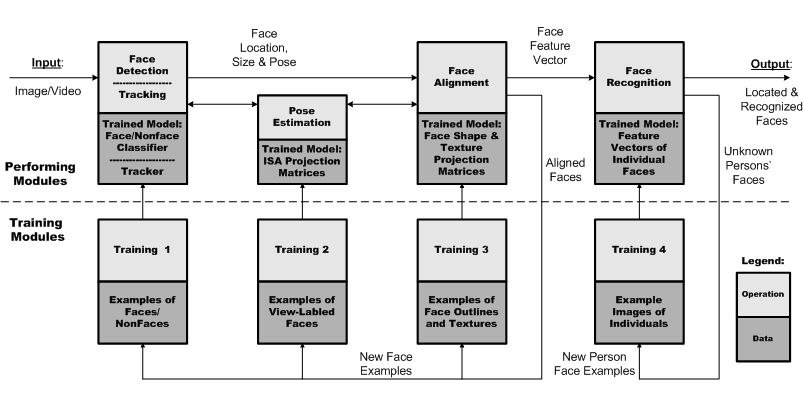
Face Detection.
The face detector inds the location and size of each face in the input image. A
detector-pyramid architecture is designed for efficient detection of multi-view
faces and a learning algorithm called FloatBoost is proposed for feature
selection and face/nonface classification therein. While the Schneiderman-Kanade
system (2000) was the first for multi-view face detection and the Viola-Jones
system (2001) was the first for real-time frontal face detection, ours is the
first real-time system for multi-view face detection.
See multi-view face detection
results.
Face Tracking. The face tracker, taking the speed advantage of the
multi-view face detector, tracks faces in video. Smoothness in time and space
from regularization is imposed as constraints on the face location and face
scale. Future speed-up may be
gained for face detection and tracking by quickly filtering out nonface areas
using color and motion information.
Pose Estimation.
The pose estimator classifies a face pattern into one of the view (pose)
groups. The pose estimate is used to verify the detection of multi-view faces,
and to help determine which of the DAM models to use for face alignment.
Supervised independent subspace analysis is applied for view-subspace learning
and view-based classification.
Face Alignment. The face alignment module spatially aligns and
warps each input face to the face of standard shape and pose in terms of both
shape and texture information. Direct appearance models, which
are shown to be more accurate and
robust than the active appearance models (Cootes et al, 1998), are used to learn
the shape and texture
subspaces and the prediction matrices. One DAM is trained for each of the L=5
view groups. A well-defined feature vector concatenating pose, shape and texture
values can then be derived from the warped face.
See multi-view face alignment
results.
Face Recognition. The face recognizer matches the faces in the input and those known faces in the database, and outputs the identity information of the seen faces. The focus in this part of research is to achieve good recognition rate with minimum number of initial training samples. A simple yet effective classification method, namely nearest feature line (NFL), which is suitable for small sample size (minimum 2 face images per person) and needs no training, and several novel linear discriminant analysis (LDA) based methods, which are formulated to cater for small sample size, are applied.
Feedbacks for Re-Training. The system has internal feedbacks to add new faces to the training sets for future re-training. Aligned faces resulting from the face alignment module can be used as additional person-nonspecific faces for re-training the face detection, pose estimation and alignment modules. Moreover, if a person is not known to the system according to the result of recognition, his/her face images may be added re-training the face recognizer. These two feedback add-on's are performed with possible interaction with the user.
Summary of
Performances.
Our face detector has a detection rate of 94%
and false alarm rate of 10-6 on our own training set of frontal
faces, as opposed to 92% and 10-6 of the Viola-Jones detector. It
takes 70 ms per frame of 320x240 pixels for frontal faces (from 20x20 to the
240x240 with size increment factor of 1.25), slightly faster than the
Viola-Jones system, on 700 MHz Pentium III notebooks. It takes 210 ms for 5-view
faces, as opposed to 1 min of the Schneiderman-Kanade system for only 4 octaves of
candidate size. Our face tracker has accuracy and speed similar to those of the
detector. The pose estimator has an accuracy of within ±20° error
range for 92% of test faces, and spends less than 1 ms per face. The face
alignment has an average reconstruction error of about 2/3 of that of AAM, yet
converges in fewer iterations with less computation for each iteration
(requiring 100 ms per face of size 64x64). Face recognition rates will be
reported soon.